在人工智能和自然语言处理的领域,长文注意力机制正逐渐成为研究的热点。近期,Kimi的新论文与DeepSeek的研究成果不谋而合,共同探讨了如何提升长文处理的效率和效果。本文将深入分析这两项研究的核心内容和创新之处。
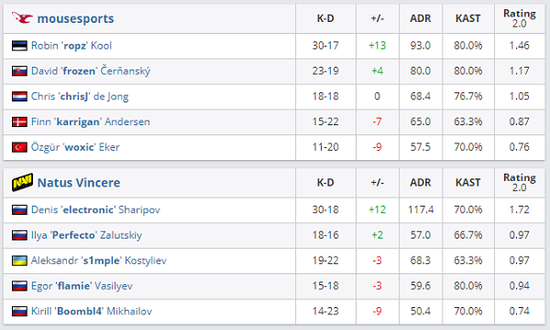
长文注意力机制的背景
长文注意力机制是指在处理长文本时,通过加强模型对重要信息的关注,从而提升文本理解和生成的能力。随着数据量的不断增加,传统的文本处理方法已难以满足需求,因此,研究者们开始探索更为高效的解决方案。
Kimi的研究成果
Kimi在其最新论文中提出了一种创新的长文注意力机制,旨在通过动态调整注意力权重,增强模型对长文本的理解能力。该研究表明,模型在处理长文本时,能够更加精准地识别出关键信息,从而提高文本生成的质量。
DeepSeek的贡献
与此同时,DeepSeek的研究同样聚焦于长文注意力机制。他们通过引入多层次的注意力机制,进一步优化了文本处理的流程。研究结果显示,该方法在多个长文本数据集上表现优异,为后续的研究提供了重要的参考。
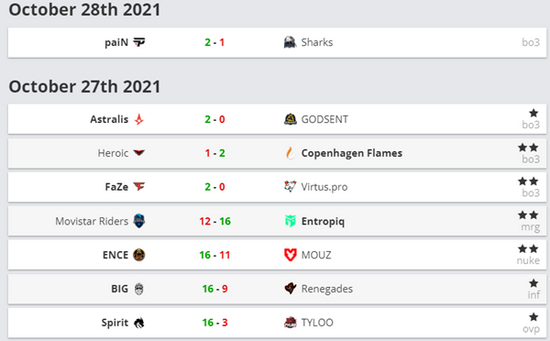
两者的比较与启示
Kimi和DeepSeek的研究虽然在方法论上有所不同,但都指向了长文处理技术的未来发展。通过对比两者的研究成果,学术界与工业界可以更好地理解长文注意力机制的应用场景,推动相关技术的落地与发展。
结语
综上所述,Kimi与DeepSeek的研究为长文注意力机制的进一步发展提供了新的视角和思路。未来,随着技术的不断进步,我们有理由相信,长文处理将会在各个领域得到更广泛的应用,助力人工智能的创新与发展。

{kind=link}